Darstellung und Analyse von Messdaten
Methoden zur Analyse von Messdaten gehören zum unabdingbaren Handwerkszeug in
der Physik. Ziel einer jeden Messung ist die Extraktion der grundlegenden
physikalischen Parameter, die von zufälligen Messunsicherheiten bzw. statistischen
Fluktuationen bei Quantenprozessen beeinflusst werden.
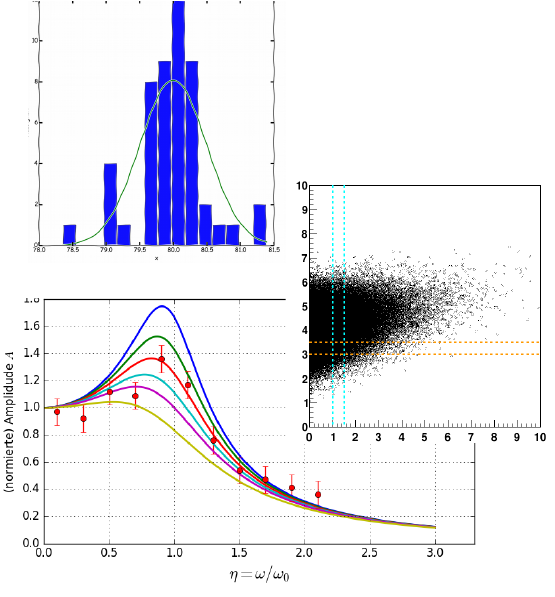 In der rein
deskriptiven Statistik, die häufig in den Sozialwissenschaften
angewandt wird, geht es um die Beschreibung von
Verteilungen von
Zufallsgrößen mit Hilfe von Lokalisierungs- und
Skalierungsparametern
(wahrscheinlichster Wert, Erwartungswert, Median,
Varianz usw.). In der inferenziellen Statistik werden konkurrierende
Modellhypothesen auf Basis der beobachteten Daten unterschieden und ggf. freie
Parameter der favorisierten Hypothese bestimmt. Typisch für die Physik ist die
Überprüfung der Verträglichkeit von Beobachtungen mit einem
theoretischen Modell,
dessen Parameter dann in einem zweiten Schritt, der Parameterschätzung,
bestimmt werden. Die Unsicherheiten der zu Grunde liegenden Beobachtungen führen
zu Unsicherheiten auf die so bestimmten Parameter. Diese Unsicherheiten werden
heute üblicherweise als Vertrauensintervalle (sog. Konfidenzintervalle)
angegeben.
In der rein
deskriptiven Statistik, die häufig in den Sozialwissenschaften
angewandt wird, geht es um die Beschreibung von
Verteilungen von
Zufallsgrößen mit Hilfe von Lokalisierungs- und
Skalierungsparametern
(wahrscheinlichster Wert, Erwartungswert, Median,
Varianz usw.). In der inferenziellen Statistik werden konkurrierende
Modellhypothesen auf Basis der beobachteten Daten unterschieden und ggf. freie
Parameter der favorisierten Hypothese bestimmt. Typisch für die Physik ist die
Überprüfung der Verträglichkeit von Beobachtungen mit einem
theoretischen Modell,
dessen Parameter dann in einem zweiten Schritt, der Parameterschätzung,
bestimmt werden. Die Unsicherheiten der zu Grunde liegenden Beobachtungen führen
zu Unsicherheiten auf die so bestimmten Parameter. Diese Unsicherheiten werden
heute üblicherweise als Vertrauensintervalle (sog. Konfidenzintervalle)
angegeben.
In der Veranstaltung „Computergestützte Datenauswertung“ und dem zugehörigen Computerpraktikum werden Methoden und Software zur grafischen Darstellung von Daten, deren Modellierung und Auswertung früh im Studium eingeführt. Dadurch wird insbesondere die Anwendung der erworbenen Kenntnisse in den später folgenden Praktika ermöglicht.
Um Reproduzierbarkeit und Wiederholbarkeit zu gewährleisten, müssen schon die grafischen Darstellungen mit einer beschreibenden Sprache erstellt werden. Als Hilfsmittel dazu bietet sich die universell einsetzbare Skript- und Programmiersprache pyhton an, die mit entsprechenden Zusatzpaketen auch die Datenverarbeitung, Durchführung von Modellanpassungen und Parameterschätzungen erlaubt. Die Arbeitsabläufe lassen sich dabei sehr komfortabel in eigene python-Programme einbetten.
Die Veranstaltung wurde erstmals im Sommersemester 2016 im Umfang von insgesamt 2 SWS angeboten. Inhalte aus der Veranstaltung „Rechnernutzung in der Physik“ aus dem fünften Semester wurden ins zweite vorgezogen und an den Kenntnisstand der Studierenden angepasst. Analytische Herleitungen wurden durch explorative Studien statistischer Zusammenhänge ergänzt bzw. ersetzt, und verstärkter Wert wurde auf die praktische Anwendung numerischer Methoden gelegt. Ein zentrales Anliegen der Veranstaltung ist es, allen Studierenden eine eigene, weitgehend standardisierte und praxistaugliche Arbeitsumgebung zur Verfügung zu stellen, innerhalb derer die Computerübungen bearbeitet werden und auf der zukünftige Kurse und eigene Anwendungen z.B. für die Bachelor-Arbeit aufbauen können.
Die empfohlene Software zum Kurs stellt diese Arbeitsumgebung bereit und ist auf allen gängigen Plattformen lauffähig (Linux, Windows, Mac, auf den Maschinen im CIP-Pool der Fakultät für Physik sowie als virtuelle Maschine unter VirtualBox). Die Visualisierung von Daten und Funktionen basiert auf der Script- und Programmiersprache python mit den Zusatzpaketen numpy und matplotlib. Neben den Grundlagen zur statistischen Datenauswertung werden auch die Modellierung von Messdaten mit der Monte-Carlo Methode sowie die Anpassung von Modellfunktionen an Messdaten behandelt. Eine reichhaltige Sammlung von python-Scripten illustriert die Zusammenhänge bzw. ermöglicht deren Studium durch selbständiges Ausprobieren.
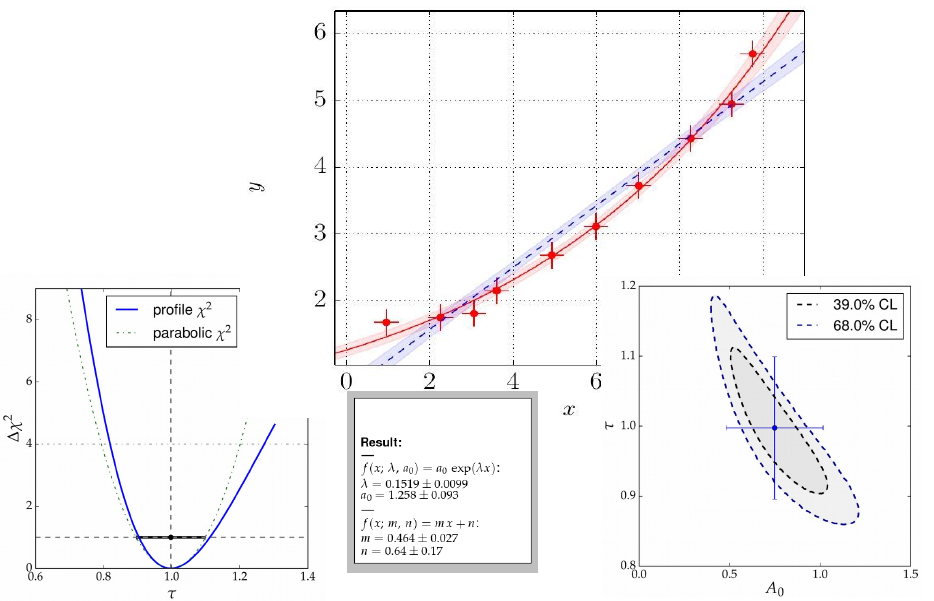 Die vorgeschlagenen
Methoden zur Datenauswertung z. B. in den Praktika zur Physik nutzen
das Paket kafe, das am Institut für Experimentelle Kernphysik
entwickelt wurde.
kafe ist ein in python geschriebenes, modulares und
erweiterbares Werkzeug, das zur numerischen Optimierung auf das am CERN
entwickelte Paket minuit zurückgreift und dessen umfangreiche
Funktionalität über ein einfaches python-Interface bereit stellt.
Unterstützt werden die Dateneingabe in verschiedenen Formaten, eine flexible
Definition von Modellfunktion(en) und umfangreiche grafische
Ausgabemöglichkeiten.
kafe kann korrelierte Unsicherheiten der Messwerte in Ordinate
und Abszisse handhaben und mit extern festgelegten oder eingeschränkten
Modellparametern umgehen. Die Visualisierung der Ergebnisse und die
Kontrolle der Qualität der Anpassung werden durch konfigurierbare
bzw. Script-gesteuerte grafische Ausgabemöglichkeiten erleichtert.
Z.B. wird der Einfluss der Parameterunsicherheiten auf das angepasste
Modell als Konfidenzband um die beste Anpassung dargestellt;
insbesondere für nichtlineare Probleme ist die grafische Darstellung
der Kovarianzmatrix der angepassen Parameter in Form von
Kovarianz-Ellipsen hilfreich.
Die vorgeschlagenen
Methoden zur Datenauswertung z. B. in den Praktika zur Physik nutzen
das Paket kafe, das am Institut für Experimentelle Kernphysik
entwickelt wurde.
kafe ist ein in python geschriebenes, modulares und
erweiterbares Werkzeug, das zur numerischen Optimierung auf das am CERN
entwickelte Paket minuit zurückgreift und dessen umfangreiche
Funktionalität über ein einfaches python-Interface bereit stellt.
Unterstützt werden die Dateneingabe in verschiedenen Formaten, eine flexible
Definition von Modellfunktion(en) und umfangreiche grafische
Ausgabemöglichkeiten.
kafe kann korrelierte Unsicherheiten der Messwerte in Ordinate
und Abszisse handhaben und mit extern festgelegten oder eingeschränkten
Modellparametern umgehen. Die Visualisierung der Ergebnisse und die
Kontrolle der Qualität der Anpassung werden durch konfigurierbare
bzw. Script-gesteuerte grafische Ausgabemöglichkeiten erleichtert.
Z.B. wird der Einfluss der Parameterunsicherheiten auf das angepasste
Modell als Konfidenzband um die beste Anpassung dargestellt;
insbesondere für nichtlineare Probleme ist die grafische Darstellung
der Kovarianzmatrix der angepassen Parameter in Form von
Kovarianz-Ellipsen hilfreich.
- Zusammenfassung der Vorlesung und Dokumentation der Code-Beispiele pdf
- Vorlesung und Starter-Kit für das Praktikum zur klassische Physik
- Code-Beispiele in python und zu kafe Dateien
- Vorlesung, Materialien und Computerübungen
- Skript: Funktionsanpassung mit der χ2-Methode
-
Funktionsanpassung in Python, Paket kafe2
(Dokumentation)
kafe2 auf GitHub Installationspaket kafe2 (whl) kafe2-master.zip
Alte Version kafe Vers. 1. (Dokumentation)
kafe Vers. 1 auf GitHub Installationspaket kafe (whl) kafe-master.zip